- description:
sddssampledist provides for psuedo-random sampling of probability
distributions. It also provides nonrandom sampling, using Halton sequences.
- example:
Draw some random samples from a normal (gaussian) distribution, G(z), shifted to have
a sigma of 10 and centroid of 5.
sddssampledist gaussian.sdds samples.sdds -samples=100 -columns=indep=z,df=G,output=zSample,factor=10,offset=5
- synopsis:
sddssampledist [input] [output] [-pipe=[in][,out]]
-columns=independentVariable=name,cdf=CDFName | df=DFName
[,output=name][,units=string][,factor=value]
[,offset=value][,datafile=filename]
[,haltonRadix=primeNumber[,randomize[,group=groupID]]]
[-columns=...] [-samples=integer] [-seed=integer]
- files:
input is the default input file for distribution functions (DFs)
and cumulative distribution functions (CDFs). input need not be
given if all -column options give the datafile qualifier.
output contains the samples. The names of the sampled data are
by default the same as the names of the independent variable from the
-column options. These names may be changed by the output
qualifier of that option.
- switches:
pipe[=input][,output] -- The standard SDDS Toolkit pipe option.
- columns=independentVariable=name,{cdf=CDFName | df=DFName}
[,output=name][,units=string][,factor=value][,offset=value]
[,datafile=filename][,haltonRadix=primeNumber[,randomize[,group=groupID]]] --
Any number this option may be given.
Specifies the CDF or DF from which to draw samples (cdf or df qualifier),
as well as the variable that the CDF or
DF depends on (independentVariable qualifier). The samples are values of this variable.
output allows specifying the name of the column for the samples, while units
allows specifying the units. factor and offset may be used to perform a simple
transformation of the sample values, according to
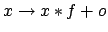 .
datafile allows specifying an alternate file as the source for the distribution function
data. By default, the data is drawn from the main input file.
haltonRadix allows specifying the radix for generation of a non-random Halton sequence,
which provides a much smoother sampling of the distribution than does a pseudo-random sequence.
The radix should be a small prime number. If you generate multiple sequences from the
same radix, they will be correlated. Hence, the randomize qualifier should be used
to remove the correlations. If there are multiple column options that should be
randomized together (i.e., randomized relative to other data but not each other), the
group qualifier can be used to assign these options to a specific *integer) group ID.
.
datafile allows specifying an alternate file as the source for the distribution function
data. By default, the data is drawn from the main input file.
haltonRadix allows specifying the radix for generation of a non-random Halton sequence,
which provides a much smoother sampling of the distribution than does a pseudo-random sequence.
The radix should be a small prime number. If you generate multiple sequences from the
same radix, they will be correlated. Hence, the randomize qualifier should be used
to remove the correlations. If there are multiple column options that should be
randomized together (i.e., randomized relative to other data but not each other), the
group qualifier can be used to assign these options to a specific *integer) group ID.
samples -- Specifies the number of samples to generate.
seed -- Specifies the seed for the random number generation. Should be a large,
odd integer. If not given, the system clock is used to generate a seed.
- author: M. Borland, ANL/APS.